

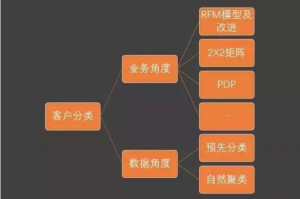
- 业务角度
- 数据角度
- 第1季讲2X2矩阵(容易理解和应用)
- 第2季讲RFM模型及改进(需要一点智商)
- 第3季讲分类和聚类(需要两斤智商)
第一季 东半球第二好用的分类模型 ,没有之一 为什么说2X2矩阵是东半球第二好用的分类模型?原因是简单直观、易于理解和解释、操作简便、适用范围广,但效力强大、几乎可以做任何事情(没有夸张)。 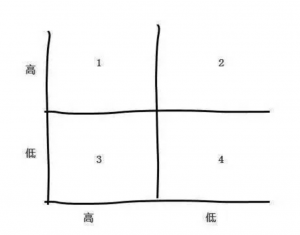
平时或多或少都听过,思路和用法各位大爷们都清楚,主要在于使用2X2矩阵的意识,它可以让你遇见问题时脑子变得非常清晰,而且能做的事情远远超过你的想象,能做的事情远远超过你的想象,能做的事情远远超过你的想象。下面是一大波栗子。 栗子1:客户价值分类 用数据分别对两个维度分类,可以使用分位数或者固定数据范围 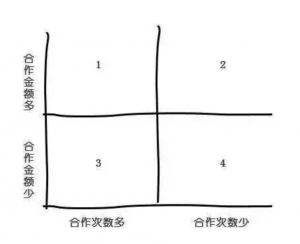
第1象限:高价值客户,注重维护关系 第2象限:重点客户,为什么合作次数少?跟竞争对手合作多吗?怎么提升合作频率? 第3象限:为什么客单价低?是客户业务性质导致还是?怎么提升客单价? 第4象限:没空搭理…自生自灭吧… 栗子2:时间管理已经见的太多了 
栗子3:员工的分类 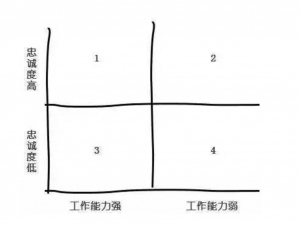
第1象限,能力强又忠诚,重点培养对象,优先考虑升职加薪,多给培训机会,培养成左右手 第2象限,能力弱但忠诚,企业中更多的是平凡的事情,需要平凡的人去做,要多给培训机会,提升能力和素质,小幅度加薪 第3象限,能力强但不忠诚,又爱又恨啊,了解忠诚度低的原因,待遇?环境? 第4象限,能力弱还不忠诚,让他滚粗 栗子4:波士顿矩阵(产品规划) 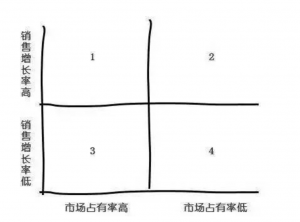
第1象限,明星产品,加大投入支持发展,适合的管理者应为对产品和销售都很内行的专家 第3象限,现金牛产品,处于成熟期,压缩投入、榨取产出,为其他产品发展提供资金,但要在维持市场地位的基础上,其管理者最好为市场营销型人物。 第2象限,问题产品,前景好但由于各种原因未打开市场(新产品),适合交给有规划能力,敢冒风险的人才。 第4象限,瘦狗产品,淘汰或合并 栗子5:女神挑汉子 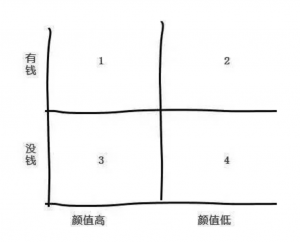
第1象限,俗称高富帅 第2象限,俗称钻石王老五 第3象限,俗称小白脸 第4现象,俗称屌丝 2X2矩阵的原理和方法都很简单,不只有客户分类,它绝大多数需要多维度考虑的事情上都适用,只要找到两个维度画出象限,你就可以看的更清、做到更多。 第二季 RFM模型在客户分类方面要比2X2矩阵细致的多。。。数据时代总得懂点数据,不然怎么装逼呢。 客户细分是用于比较的,比较是为了反映差异进而做出调整优化,所以细分的目的最终还是指导运营决策。 上一回书说到2X2矩阵,简便易行且适用范围非常广,但同时2X2矩阵的分类也有缺点,分类的维度只有2个,当业务指标大于2个时无能为力,总体而言2X2矩阵不失为一种快速有效的分类方法。 今天要介绍的RFM模型在客户分类方法中的地位举足轻重,是衡量客户价值和客户创利能力的重要工具和手段,本篇文章会详细讲解RFM模型及改进方法,主要内容包括RFM介绍和AHP层次分析法,各位看官您请看。 还记得2X2矩阵的第一个栗子么? 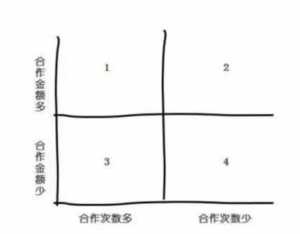
在矩阵基础上再增加一个维度R(Recently,意为最近一次消费时间),这就是我们今天要讲的RFM模型,上图给你看。 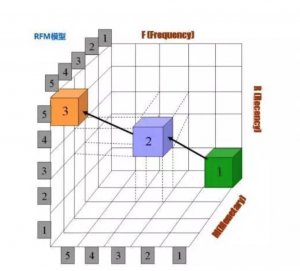
其中R近度(Recency) 代表最近购买时间,指上次购买至现在的时间间隔; F 频度(Frequency)代表购买频率,指的是某一期间内购买的次数;M额度(Monetary) 代表总购买金额,指的是某一期间内购买商品的金额。 美国数据库营销研究所Arthur Hughe研究表明 - R值越小,越可能再次购买
- F值越大,越可能再次购买
- M值越大,越可能再次购买
每个维度分为5个梯度,这就有5*5*5=125种客户类型,看图。 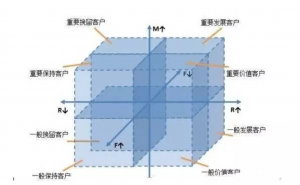
这就是典型的RFM模型,很简单吧,嘿嘿嘿 什么什么?你以为这就是全部?做梦!!典型的RFM有很多缺点,根本不能直接照搬使用! - 创造RFM模型的Arthur Hughe认为三个指标的权重是一致的,但Stone Bob经过实证验证权重不一致,实际上由于业务的不同,各个行业之间的权重都是不一样的
- 典型的RFM把客户分为125类,尼玛啊,这么多类型在营销实战中根本做不到差异化的运营策略好嘛!!
- 典型的RFM只有分类,但却不知道各个类别之间的客户到底哪个更有忠诚度和价值
接下来用层次分析法确定权重 然后让他们填表,唉,有点枯燥,估计今天这篇文章发出去得掉粉啊…伤心… 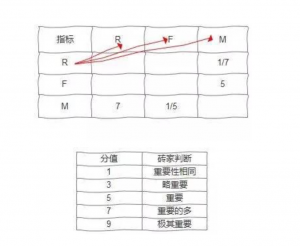
填表的规则是这样,拿每一行两两对比每一列,如果砖家判断行比列的重要性由右上图,就填相应的数字,反过来就填相应数字的倒数,什么意思呢举个栗子 - 砖家认为F值比M值重要,在3行4列填5,那么4行3列填1/5
- 砖家认为M值比R值重要的多,在4行2列填7,那么2行4列填1/7
以此类推 砖家填完之后,我们就拿到了一份数据表格,命名为矩阵A 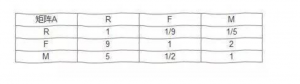
你以为这就完了?耐心点看完,上班了好装X 接下来就数据进行归一化处理,先对每一列求和,然后算出每一列各个元素的占比,得到矩阵B 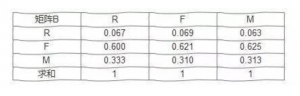
再对每一行求和,就得到特征向量W 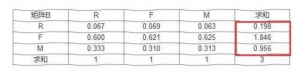
再对特征向量归一化处理,每个元素除以列之和(就是除以3嘛),就得到了各指标的权重! 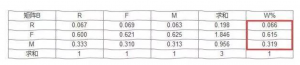
真不好意思…还没完…耐心… 权重是不是对的呢?鬼知道砖家填表有没有逻辑错误,比如A>B,B>C,那么A肯定>C啊,但是砖家填C>A,很明显不符合逻辑,所以要做一致性验证 计算矩阵最大特征根 用矩阵A乘以权重列W%,得到一个列向量,然后用列向量中每一个元素除以矩阵阶数和相对应的权重乘积,公式如下 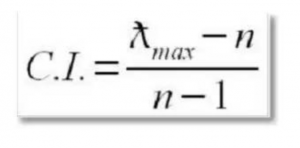
结果为 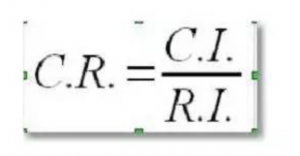
R.I.是固定的,根据矩阵阶数查表为0.52 
随机一致性比率C.R.=0.00062/0.52=0.001186<0.1,注意只有当随机一致性比率小于0.1时,才说明砖家填的表是没有逻辑错误…, 那么我们就可以确定,R\F\M指标的权重是 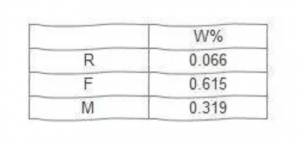
我知道你们都要晕了,说实话我也晕的不行… 第三季 重点介绍下数据挖掘中的聚类,完成客户分类的最后一步,并且对各个类别的客户进行忠诚度和价值评分,这才是我们的最终目的。也是最重要的部分,之前的内容都在为本季做铺垫,终于到出最终结果的时候,有一种蛋蛋的忧伤… - 找到最有价值的TA(一)
介绍2X2矩阵的各种常见或不常见用法,几乎能做任何事情 - 找到最有价值的TA(二)
客户价值分类中使用最广泛的RFM模型和改进、以及层次分析法确定权重 - 找到最有价值的TA(三)
用聚类(K-means)方法完成客户分类并评估各类客户价值 聚类到底是什么鬼 从数据层面划分的方法有两种:分类和聚类 举个栗子,新学期分班,一大坨陌生的尼玛们坐在教室里,老师进来后说:“女生坐在第一排,男生坐在第二排,人妖坐在第三排”,人为的通过某种方式划分,这就叫分类方法,具体有决策树、神经网络等 尼玛们过了几天,互相熟悉之后自发的分为很多小群体,比如李雷、韩梅梅、吉姆格林他们三个就喜欢天天腻在一起玩,因为他们的性格、爱好都比较相近。没有人为给定规则、完全由数据本身自发的分类,这就叫聚类方法,具体方法有层次聚类、K-means等 我们今天要做的,就是使用K-means聚类方法完成最终的客户分类,各位大爷您请往下看 帮隔壁老王做客户分类 隔壁老王有一家淘宝小店,一天他来找你帮忙 为了老王的家庭和谐,勉为其难的答应吧… 我们先来研究下老王的销售数据,分为5个字段,正好满足RFM模型的数据要求(R-最近一次购买时间,F-购买次数,M-购买金额) 
先处理老王的基础销售数据,使其符合RFM模型的数据格式,变成下面这样 
接着对数据加权和标准化。 K-means聚类 K-means的聚类思想非常简单 - 首先确定聚成n类
- 随机指定n个初始点,计算所有点到这n个点的距离,距离最近的归为一类
- 计算每一类的平均坐标,以此为新的初始点,循环以上过程直至中心点位置不再变化为止
现在回到老王的数据上,我们首先确定聚类的数量,通过每类顾客RFM平均值和总RFM平均值相比较,而单个指标比较只有两种情况:>=平均值或者<平均值,这样就有2*2*2=8种类别。 操作上用SAS或SPSS一分钟搞定~~ 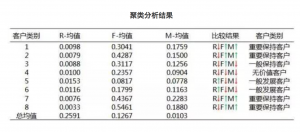 通过RFM聚类,我们把客户分为了重要保持、一般保持、一般发展、无价值四类,终于可以打发隔壁老王这个王八蛋,但是他又有意见了。老王说的是个问题,所以我们要做顾客价值评分,聚类前做了数据标准化和加权,所以每类顾客的价值评分只需要把RFM三个指标的均值相加就可以啦~~~
通过RFM聚类,我们把客户分为了重要保持、一般保持、一般发展、无价值四类,终于可以打发隔壁老王这个王八蛋,但是他又有意见了。老王说的是个问题,所以我们要做顾客价值评分,聚类前做了数据标准化和加权,所以每类顾客的价值评分只需要把RFM三个指标的均值相加就可以啦~~~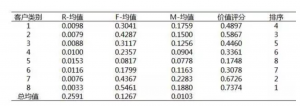 对每一类做价值评分可以量化各类客户的价值差别,弥补客户分类的不足,由于受到成本制约,老王只能将资源集中在更高价值的客户身上,有助于制定更为可行的决策。
对每一类做价值评分可以量化各类客户的价值差别,弥补客户分类的不足,由于受到成本制约,老王只能将资源集中在更高价值的客户身上,有助于制定更为可行的决策。




